ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning
https://openreview.net/forum?id=r1xMH1BtvB
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than...
A text encoder trained to distinguish real input tokens from plausible fakes efficiently learns effective language representations.
openreview.net
MLM (Masked Language Modeling)
Masked Language Modeling에서 입력 시퀀스의 토큰의 특정 비율이 [MASK] 토큰으로 바뀝니다. 그리고 Left-to-Right 혹은 Right-to-Left를 통하여 문장 전체를 예측(Predict)하는 방법과는 달리, [MASK] 토큰 만을 예측하는 사전훈련(Pre-training) 작업(task)를 수행합니다. 이 [MASK] 토큰은 사전 훈련에만 사용되고, Fine-tuning 시에는 적용되지 않습니다. 입력 문장에서 임의로 토큰을 마스킹하고, 해당 토큰을 맞추어 내는 작업을 수행하면서 문맥을 파악하는 능력(문장의 빈칸 채우는 능력)을 길러낸다고 생각하시면 됩니다.
구체적인 학습방식은 입력 문장의 15%를 임의의 토큰으로 대체하고, 이 임의의 토큰이 어떤 단어인지 예측하는 방식입니다. 이때 바뀌어지는 임의의 토큰이라고 불리는 15%는 80%는 [MASK]로 10%는 Random Word로 나머지 10%는 원래 단어로 그대로 두어 학습 시 올바른 예측을 돕도록 마스킹에 노이즈를 섞는 방식입니다.
그렇기 때문에 MLM 접근 방식은 주어진 예의 마스킹 된 토큰(일반적으로 15%)에서만 학습이 된다고 합니다. 이로 인해 MLM을 사용하여 언어 모델을 학습하는 데 필요한 계산 리소스가 크게 증가합니다. 이 때문에 대안으로 Replaced Token Detection Task를 제안합니다.
ELECTRA
RTD (Replaced Token Detection)
ELECTRA는 모든 입력 위체에서 학습하면서 양방향 모델을 학습시키는 대체 토큰 감지(RTD)라고 하는 새로운 사전 학습 작업을 사용합니다. Generative Adversarial Networks(GANs)에서 영감을 받은 이 작업은 BERT와 같이 토큰을 [MASK]로 대체하여 입력을 손상(corrupting)하는 대신 ELECTRA 모델이 "진짜"와 "가짜" 입력 데이터를 구분하는 훈련을 합니다.
이 논문에서 접근 방식은 일부 입력 토큰을 잘못되었지만 다소 그럴듯한 가짜 토큰으로 대체하여 입력을 손상시킵니다. 예를 들면 아래와 같이"요리사가 음식을 요리했다."를 "요리사가 음식을 먹었다."로 대체할 수 있습니다.
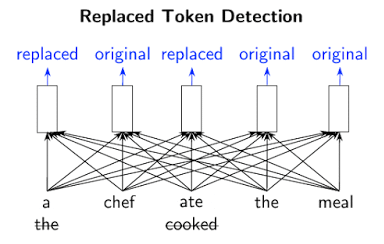
이것은 말이되지만 전체적 의미는 다릅니다. 사전 훈련 작업에는 모델 판별기(Discriminator)이 원래 입력에서 어떤 토큰이 교체되었거나 동일하게 유지되었는지를 확인합니다. 이러한 이진 분류 작업은 적은 수의 마스킹 된 토큰 대신 모든 입력 토큰에 적용되어 RTD를 MLM보다 효율적으로 만듭니다. 따라서 ELECTRA는 더 적은 데이터(예제)를 보고, 예제별로 모든 훈련을 받기 때문에 동일한 성능을 발휘합니다. 동시에 RTD는 작업을 해결하기 위해 모델이 데이터 분포의 정확한 표현을 학습하기 때문에 강력한 표현 학습으로 이어집니다.
대체 토큰은 생성기(Generator0라는 다른 신경망에서 나옵니다. 생성기는 토큰에 대한 출력 분포를 생성하는 모든 모델이 될 수 있지만, 이 논문에서는 판별기와 함께 훈련된 작은 마스킹 된 언어 모델(hidden_size가 작은 BERT 모델, small MLM)을 사용합니다. 판별기에 공급하는 생성기 구조는 GAN과 유사하지만 GAN을 텍스트에 적용하기가 어렵기 때문에 마스킹된 단어를 예측할 가능성이 최대가 되도록 생성기를 훈련합니다. 생성기와 판별기는 동일한 입력 단어 임베딩을 공유합니다. 사전 훈련 후 생성기는 삭제되고 판별기(ELECTRA model)는 다운 스트림 작업에서 미세 조정됩니다. 이 모델은 모두 Transformer를 사용하는 아키텍쳐입니다.
Result
ELECTRA는 다른 최첨단(State-of-the-art) NLP 모델과 비교한 결과 동일한 컴퓨팅 자원을 고려할 때 이전 방법보다 크게 향상되어 컴퓨팅 자원의 25% 미만을 사용하면서 RoBERTa 및 XLNet과 비슷한 성능을 발휘한다는 것을 발견했습니다.

효율성의 한계를 넘어 4일만에 단일 GPU에서 우수한 정확도로 훈련할 수 있는 작은 ELECTRA 모델을 실험해본 결과 학습하는데 많은 TPU가 필요한 더 큰 모델과 동일한 정확도를 달성하지는 못했지만 ELECTRA-small은 성능이 매우 뛰어나며 컴퓨팅의 1/30만 필요하면서 GPT를 능가합니다.
마지막으로 강력한 결과가 대규모로 유지되는지 확인하기 위해 더 많은 컴퓨팅 자원을 사용하여 대규모 모델을 훈련한 결과 이 모델은 SQuAD 2.0 Question and Answering Dataset에서 단일 모델에 대한 최첨담 성능을 달성하고 다른 모델들을 능가합니다.

이 논문에서는 ELECTRA를 사전 학습하고 다운 스트림 작업에서 미세 조정하기 위한 코드를 출시하고 있으며 현재 지원되는 작업에는 텍스트 분류, 질문 답변 및 시퀀스 태깅이 포함되어 있습니다. 이 코드는 하나의 GPU에서 작은 ELECTRA 모델을 빠르게 훈련하는 것을 지원합니다.
ELECTRA-Large, base, small에 대한 사전 훈련 가중치도 출시되어 있습니다. 현재 영어로만 제공되지만 후에 여러 언어로 사전 학습된 모델을 출시할 예정입니다.
'NLP 자연어 처리, Natural Language Processing' 카테고리의 다른 글
| 부트스트랩, Bootstrap in ML (0) | 2021.02.17 |
|---|---|
| 나만의 Tokenizer, vocab 만들기 (0) | 2021.02.02 |
| RealFormer: Transformer Likes Residual Attention (0) | 2021.01.19 |
| 네이버 개발자센터(NAVER Developers), 번역 API 사용해보기 (0) | 2021.01.07 |
| BLEU score (Bilingual Evaluation Understudy score) (0) | 2020.12.21 |



